Chat Memory는 저장소 선택부터 설계가 시작된다
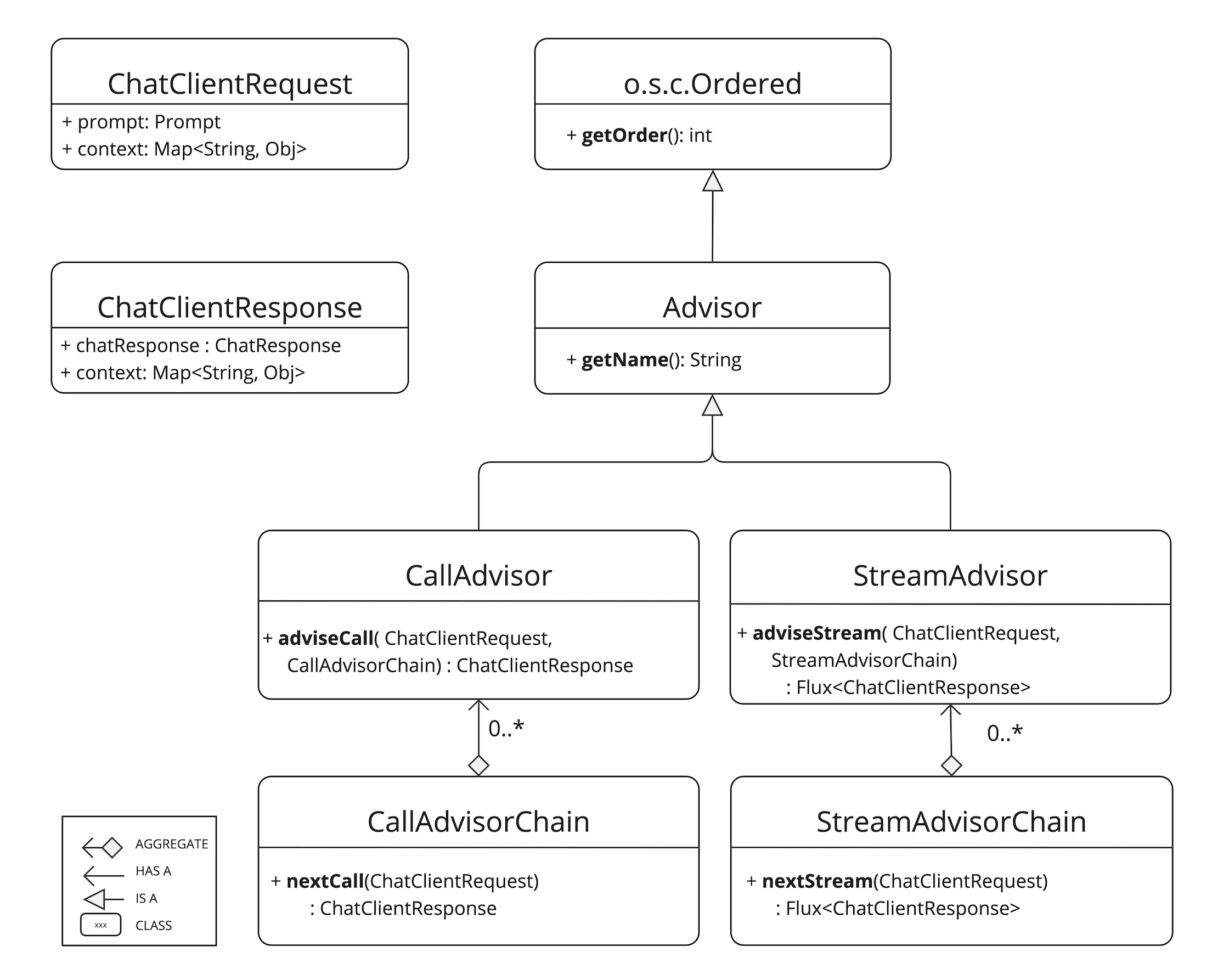
ChatClient와 RAG를 이해하고 나면 곧바로 부딪히는 질문이 있다.
대화 이력은 어디에 둘 것인가?
데모에서는 한 번 호출하고 끝나지만, 실제 서비스는 다르다.
- 이전에 사용자가 무엇을 물었는지 기억해야 하고
- 도구 호출 결과도 문맥으로 다시 써야 할 때가 있고
- 세션이 끊겨도 기록을 유지해야 할 수 있으며
- 운영 환경에서는 감사 추적이나 TTL 정책도 필요하다
Spring AI의 Chat Memory 문서는 이 문제를 단순한 “메시지 리스트 저장”이 아니라, 어떤 저장소에 어떤 수명과 질의 방식으로 대화 문맥을 유지할지의 문제로 다룬다.
Chat Memory를 너무 단순하게 보면 안 되는 이유
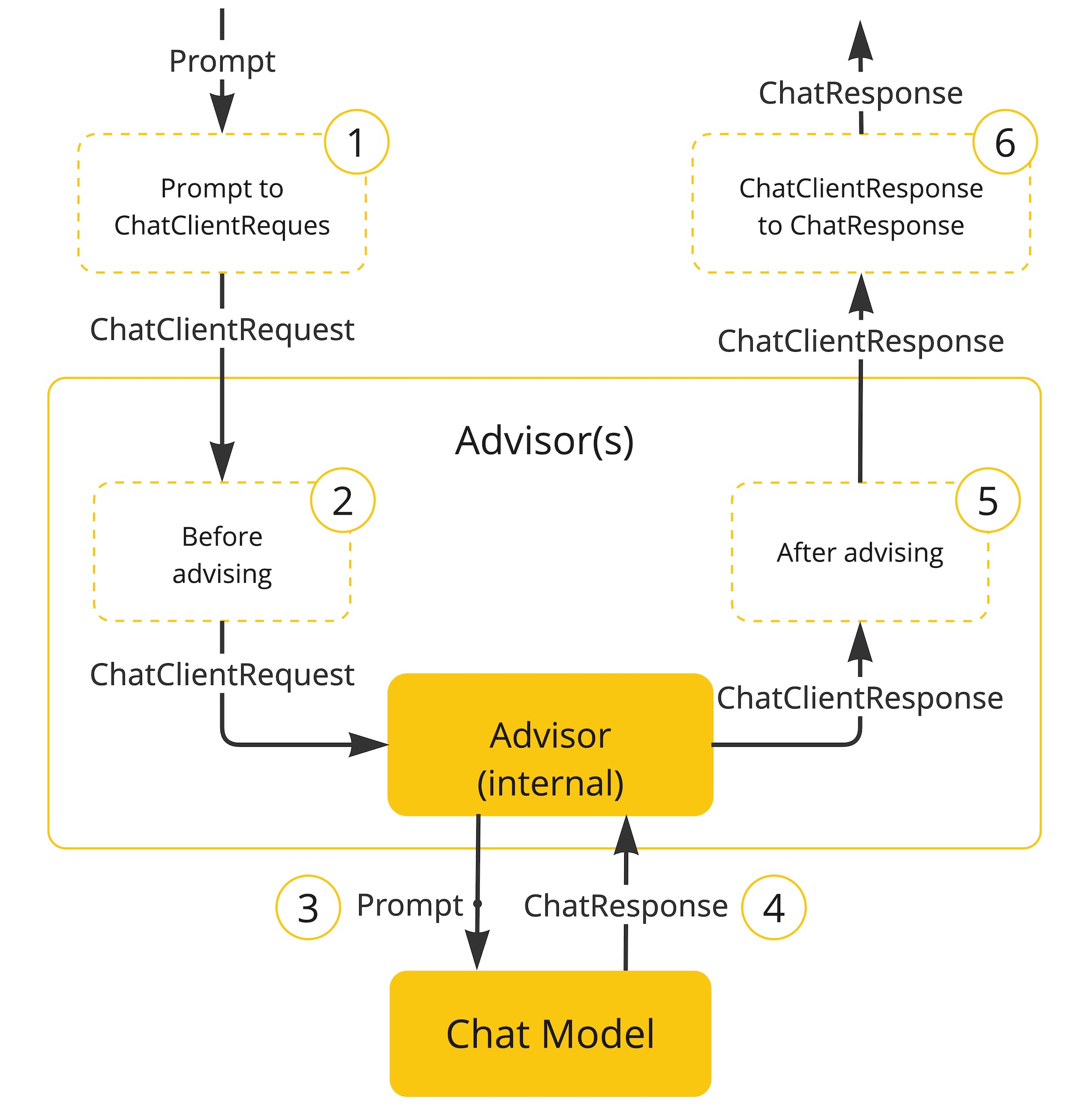
대화 메모리는 얼핏 쉬워 보인다.
“최근 메시지 몇 개를 저장했다가 다시 넣으면 되는 것 아닌가?”
작게 보면 맞다. 하지만 서비스가 커지면 금방 다른 요구가 나온다.
- 메모리를 메모리 안에만 둘 것인가, DB에 영속화할 것인가
- 대화 이력을 전부 남길 것인가, 최근 윈도우만 볼 것인가
- 메시지 TTL이 필요한가
- 검색형 조회가 필요한가
- 메시지 외 메타데이터, 툴 호출, 미디어까지 함께 남길 것인가
그래서 Spring AI는 ChatMemoryRepository라는 추상화를 두고, 저장소 구현을 바꿀 수 있게 설계한다.
기본값: In-Memory는 가장 쉬운 출발점이다
문서에서 가장 먼저 나오는 구현은 InMemoryChatMemoryRepository다.
이 구현의 장점은 명확하다.
- 추가 인프라가 필요 없다
- 로컬 개발이나 빠른 데모에 적합하다
- Spring Boot 자동 설정으로 바로 시작하기 쉽다
즉 “일단 대화 메모리 개념을 붙여 보는” 단계에서는 가장 부담이 적다.
하지만 한계도 명확하다.
- 프로세스가 내려가면 기록이 사라진다
- 다중 인스턴스 환경에서 공유가 어렵다
- 운영용 감사 기록이나 장기 유지에는 맞지 않는다
그래서 In-Memory는 개념 확인과 로컬 개발용 기본값 정도로 이해하는 편이 좋다.
JDBC 저장소: 가장 현실적인 영속화 시작점
문서에서 가장 실무적으로 눈에 들어오는 구현은 JdbcChatMemoryRepository다.
이 저장소는 관계형 DB를 사용하고, Spring 팀이 여러 벤더용 dialect를 기본 제공한다.
- PostgreSQL
- MySQL / MariaDB
- SQL Server
- HSQLDB
- Oracle
이 선택이 좋은 이유는 운영 현실과 잘 맞기 때문이다.
대부분의 팀은 이미 RDB를 쓰고 있고, 대화 메모리를 위해 새로운 저장소를 당장 늘리고 싶지 않을 수 있다. 그런 팀에게 JDBC 저장소는 꽤 자연스러운 기본값이 된다.
문서가 schema 초기화 옵션을 따로 설명하는 이유도 여기에 있다.
- 개발 환경에선 자동 생성이 편하고
- 운영 환경에선 Flyway/Liquibase와 충돌하지 않게 제어해야 하며
- DB 벤더별 스크립트 경로도 달라질 수 있기 때문이다
즉 JDBC 저장소는 단순 기능보다 운영 제어성이 장점이다.
Cassandra: 대화 로그를 장기간, 시계열적으로 남기고 싶을 때
CassandraChatMemoryRepository는 꽤 성격이 다르다.
문서가 강조하듯 이 저장소는 time-series 성격을 갖고, TTL과 장기 보관, 가용성, 내구성 같은 장점이 있다.
이 구현이 어울리는 경우는 대체로 이런 쪽이다.
- 대화 이력을 오래 남겨야 하는 서비스
- 거버넌스나 감사 요구가 있는 환경
- 대량 트래픽과 장기 보관이 동시에 필요한 경우
즉 “챗봇이 이전 대화를 좀 기억하면 좋겠다” 수준보다, 대화 기록 자체가 운영 데이터가 되는 환경에 더 가깝다.
Neo4j: 메시지를 그래프로 다루고 싶을 때
Neo4jChatMemoryRepository는 다른 저장소보다 조금 독특하다.
문서 설명 그대로, 메시지를 노드와 관계로 저장한다. 이건 단순 영속화보다 관계 탐색이 중요한 경우에 흥미롭다.
예를 들어,
- 어떤 세션에서 어떤 툴 호출이 이어졌는지
- 메시지와 메타데이터, 미디어 사이 관계를 그래프 형태로 보고 싶은지
- 추후 분석 쿼리를 더 유연하게 하고 싶은지
같은 요구가 있을 때 의미가 있다.
물론 대부분의 일반적인 챗봇은 여기까지 필요하지 않을 수 있다. 그래서 Neo4j는 보편적 기본값이라기보다, 그래프 모델링 이점이 분명할 때 선택하는 저장소에 가깝다.
Cosmos DB, MongoDB: 문서 지향 영속화가 더 잘 맞는 경우
문서에는 CosmosDBChatMemoryRepository, MongoChatMemoryRepository도 나온다.
이 둘은 공통적으로 문서 지향 저장 방식과 잘 맞는다.
Cosmos DB
- 전역 분산
- 높은 확장성
- 대화 ID를 파티션 키로 삼는 구조
이런 특징 때문에 Azure 기반 서비스에서 운영 편의가 좋다.
MongoDB
- 유연한 문서 구조
- 빠른 시작과 직관적인 데이터 저장
- TTL 인덱스 같은 운영 옵션 활용 가능
즉 이미 문서 DB 기반 운영 체계가 있다면, 대화 메모리도 그 위에 자연스럽게 올릴 수 있다.
Redis: 빠른 응답과 TTL, 검색형 조회가 같이 필요할 때
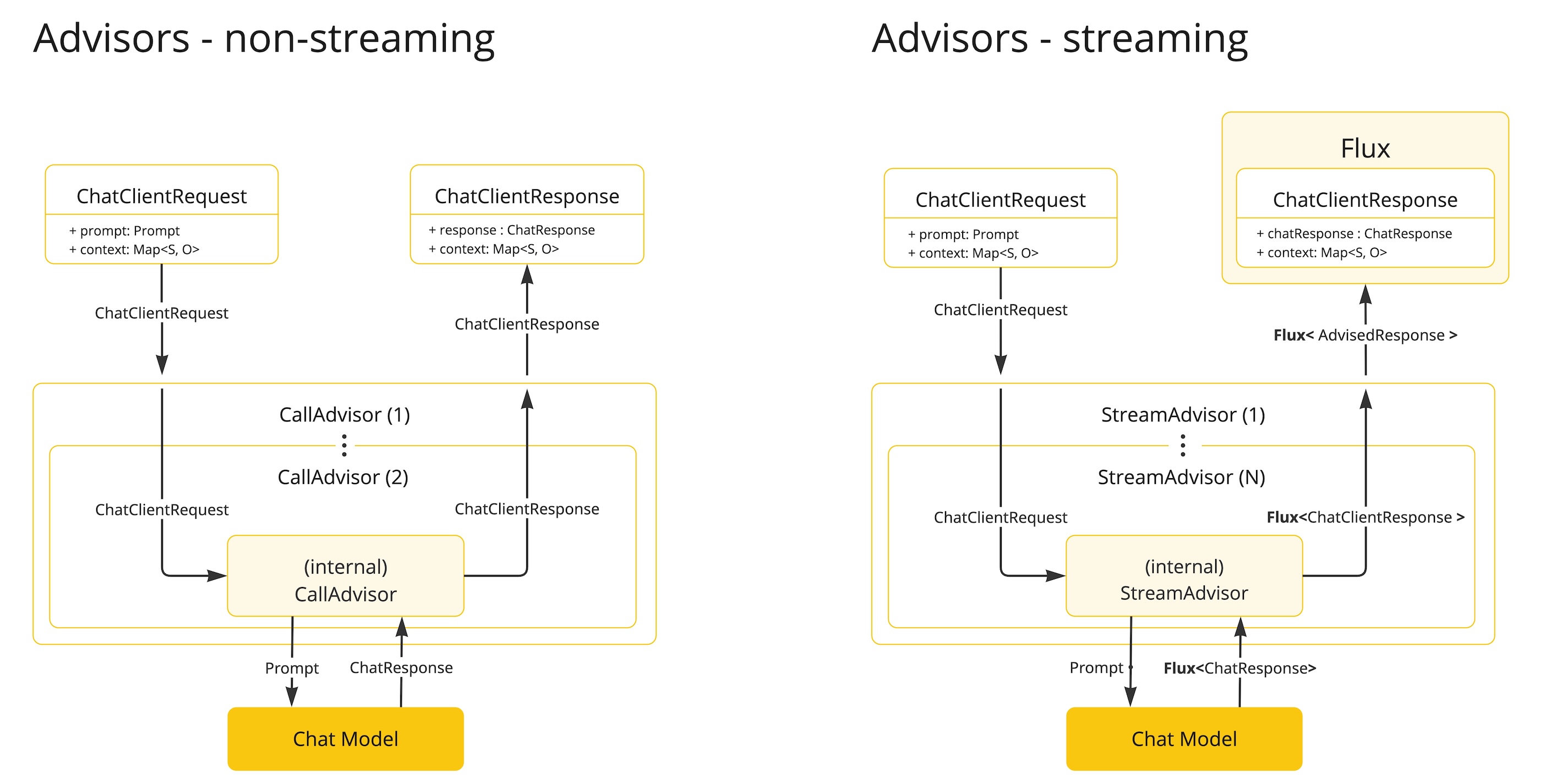
문서에서 개인적으로 가장 흥미로운 구현 중 하나는 RedisChatMemoryRepository다.
이 저장소는 단순 key-value 캐시처럼만 쓰는 게 아니라,
- JSON 문서 저장
- 검색 인덱스 생성
- TTL 지원
- 메시지 유형/시간 범위/메타데이터 기반 조회
까지 제공한다.
이건 꽤 실무적이다.
예를 들어,
- 최근 대화 맥락을 빠르게 읽어야 하고
- 오래된 메시지는 자연스럽게 만료시키고 싶고
- 특정 유형의 메시지만 다시 보고 싶고
- 운영 중 검색형 분석도 조금 필요하다
같은 상황이라면 Redis가 매우 현실적인 선택이 될 수 있다.
다만 문서가 말하듯 Redis Stack과 관련 모듈이 필요하므로, 그냥 “Redis 있으니까 바로 된다” 수준은 아니다. 인프라 조건도 같이 봐야 한다.
결국 저장소 선택 기준은 이것이다
문서를 다 읽고 나면, 선택 기준은 제품 이름보다 요구사항으로 정리된다.
1) 그냥 개발/데모 단계인가
InMemory
2) 이미 RDB를 운영 중이고 무난한 영속화가 필요한가
JDBC
3) 장기 보관, TTL, 감사 추적, 대규모 이력이 중요한가
Cassandra
4) 관계형 탐색이나 그래프 분석 가치가 있는가
Neo4j
5) 문서 지향 저장과 클라우드 스케일이 중요한가
Cosmos DB,MongoDB
6) 초저지연 + TTL + 검색형 조회가 필요한가
Redis
즉 Chat Memory 저장소는 “어느 DB가 더 멋진가”가 아니라, 대화 기록을 어떤 운영 자산으로 볼 것인가의 문제다.
Message Window와 함께 봐야 한다
문서 예제는 대부분 저장소를 MessageWindowChatMemory와 같이 보여 준다. 이건 중요하다.
저장소가 모든 메시지를 영속화하더라도, 실제 프롬프트에 다시 넣는 메모리는 보통 최근 윈도우 중심으로 다룬다. 즉 두 층을 구분해야 한다.
- 저장소: 얼마나 오래, 어디에, 어떤 형식으로 보관할지
- 메모리 윈도우: 실제 호출 시 얼마나 다시 넣을지
이 구분이 있어야 “저장은 많이 하되, 프롬프트는 가볍게 유지”하는 설계가 가능하다.
실무에서 먼저 물어봐야 할 질문
Chat Memory를 붙이기 전에 아래 질문을 먼저 던지는 편이 좋다.
- 세션이 재시작돼도 이전 대화를 기억해야 하는가
- 사용자별 장기 이력을 남겨야 하는가
- TTL이 필요한가
- 감사 추적이나 규제 요구가 있는가
- 다중 인스턴스 환경에서 메모리를 공유해야 하는가
- 최근 대화만 필요한가, 검색형 조회도 필요한가
이 질문에 답하면 저장소 후보가 꽤 빨리 좁혀진다.
마무리
Spring AI의 Chat Memory 문서는 단순히 저장소 목록을 나열하는 문서가 아니다.
오히려 “대화 메모리”를 어떤 수준의 운영 문제로 볼 것인지 정리하게 해 준다.
- In-Memory는 가장 빠른 출발점이고
- JDBC는 현실적인 영속화 기본값이며
- Cassandra·Redis·Neo4j·MongoDB·Cosmos DB는 각기 다른 운영 요구를 반영한다
중요한 건 저장소 선택 자체보다, 대화 기록을 일회성 문맥으로 볼지, 운영 데이터로 볼지를 먼저 결정하는 일이다.