ChatClient가 사실상 Spring AI의 진입점인 이유
Spring AI 문서를 읽다 보면 결국 가장 먼저 손에 익게 되는 클래스가 ChatClient다.
이유는 단순하다. 실제 애플리케이션에서 개발자가 제일 먼저 하고 싶은 일은 늘 비슷하기 때문이다.
- 사용자 입력을 모델에 보내고
- 시스템 규칙을 함께 넣고
- 응답을 문자열이나 구조화된 결과로 받고
- 필요하면 스트리밍으로 UI에 흘려보내는 것
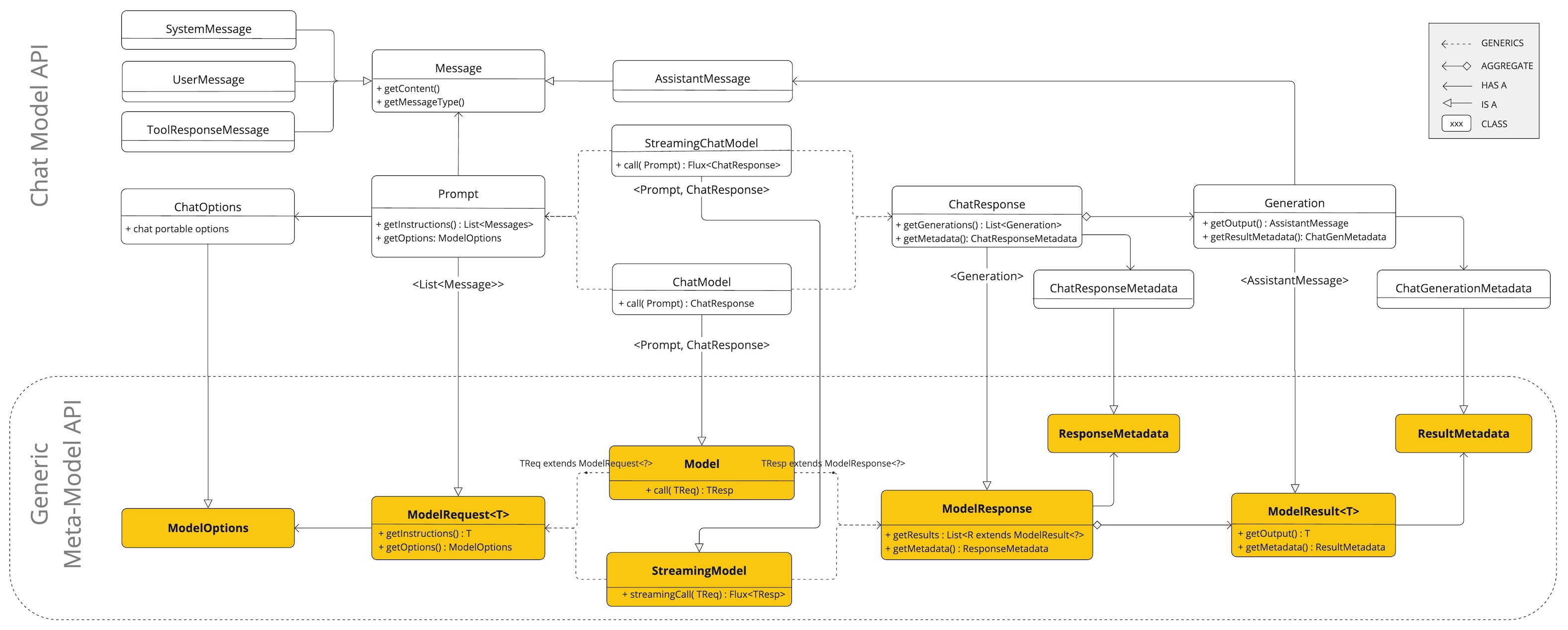
ChatClient는 바로 이 출발점을 담당한다. 문서 표현대로 보면 fluent API를 통해 프롬프트의 구성 요소를 조립하고, 그 결과를 AI 모델에 전달하는 인터페이스다.
쉽게 말해 Spring AI에서 ChatClient는 “첫 번째 호출이 가장 자연스럽게 시작되는 곳”이다.
가장 단순한 예제는 왜 중요한가
문서에 나오는 가장 기본적인 예제는 대략 이런 형태다.
1@RestController2class MyController {34 private final ChatClient chatClient;56 public MyController(ChatClient.Builder chatClientBuilder) {7 this.chatClient = chatClientBuilder.build();8 }910 @GetMapping("/ai")11 String generation(String userInput) {12 return this.chatClient.prompt()13 .user(userInput)14 .call()15 .content();16 }17}18이 코드는 단순하지만 Spring AI의 핵심 감각을 거의 다 보여 준다.
ChatClient.Builder는 Spring Boot가 자동 설정해 줄 수 있다.prompt()에서 요청을 시작한다.user(...)로 사용자 메시지를 넣는다.call()로 실제 호출을 수행한다.content()로 텍스트 응답만 꺼낸다.
즉 모델 호출이 “SDK 객체를 직접 두드리는 코드”보다, Spring 서비스 안에서 읽히는 흐름으로 정리된다.
prompt가 왜 메서드 체이닝으로 보일까
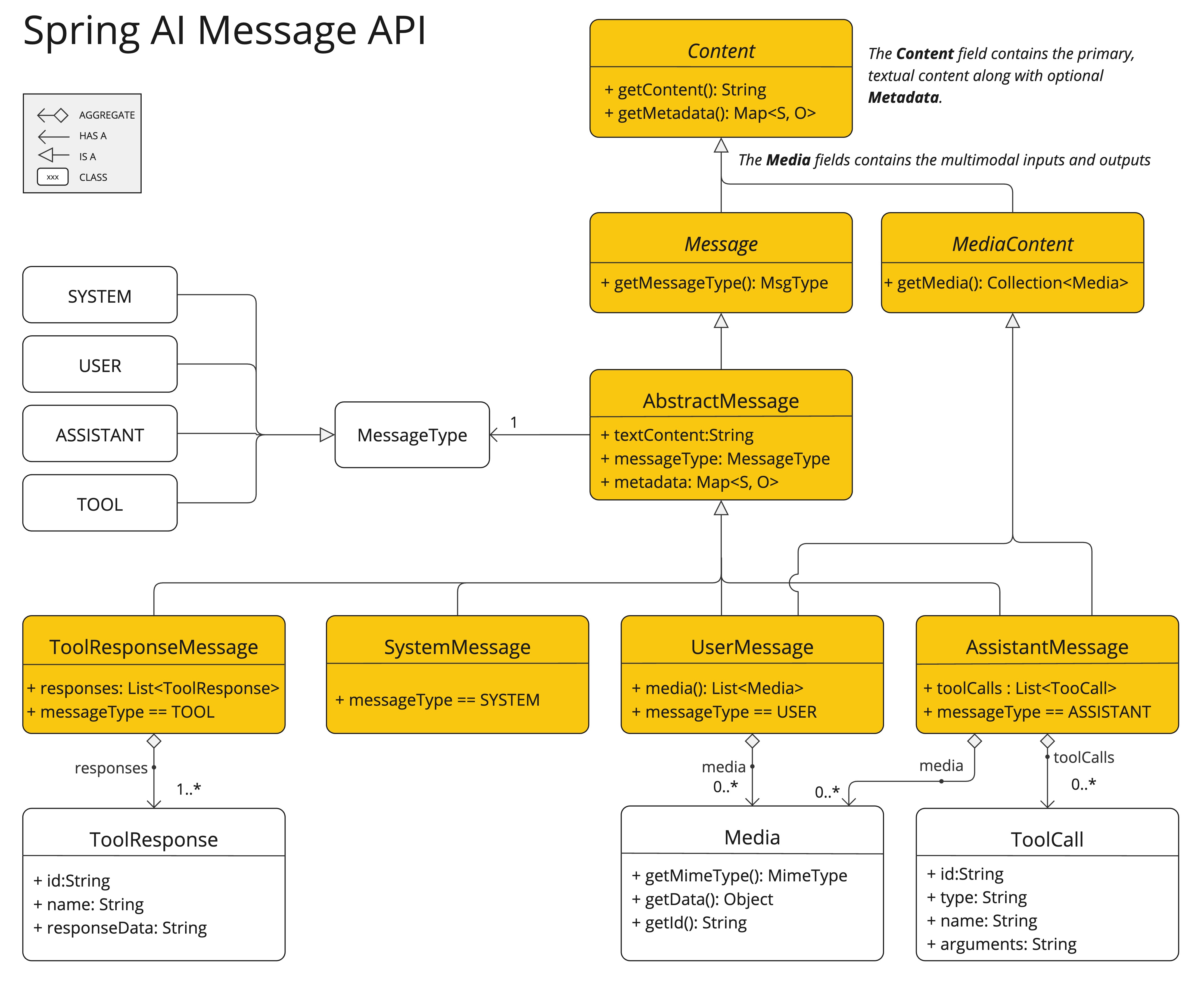
이건 단순히 예쁘게 보이기 위한 문법이 아니다. Spring AI가 프롬프트를 문자열 한 줄이 아니라 구성 가능한 메시지 묶음으로 보기 때문이다.
보통 여기서 조합하게 되는 건 이런 것들이다.
- 사용자 메시지
- 시스템 메시지
- 모델 옵션
- advisor 체인
- 툴 정보
- 스트리밍 여부
그래서 ChatClient는 체이닝이 잘 어울린다. 요청 한 건을 점진적으로 조립하는 감각이기 때문이다.
system과 user를 분리하는 습관이 중요하다
LLM 앱을 처음 만들 때 흔히 하는 실수는 모든 지시를 하나의 문자열로 몰아넣는 것이다. 하지만 Spring AI는 현대 LLM API의 기본 감각을 그대로 따른다.
system: 모델의 역할, 제약, 답변 톤, 금지 사항user: 실제 요청
이 둘을 분리하면 좋은 점이 많다.
- 프롬프트 의도가 명확해진다.
- 재사용 가능한 시스템 규칙을 분리할 수 있다.
- 나중에 메모리, RAG, Tool Calling을 붙여도 구조가 덜 무너진다.
즉 ChatClient는 단순 호출 API라기보다, 나중에 복잡한 흐름으로 확장될 수 있는 프롬프트 조립 지점이라고 보는 편이 맞다.
Builder가 중요한 이유
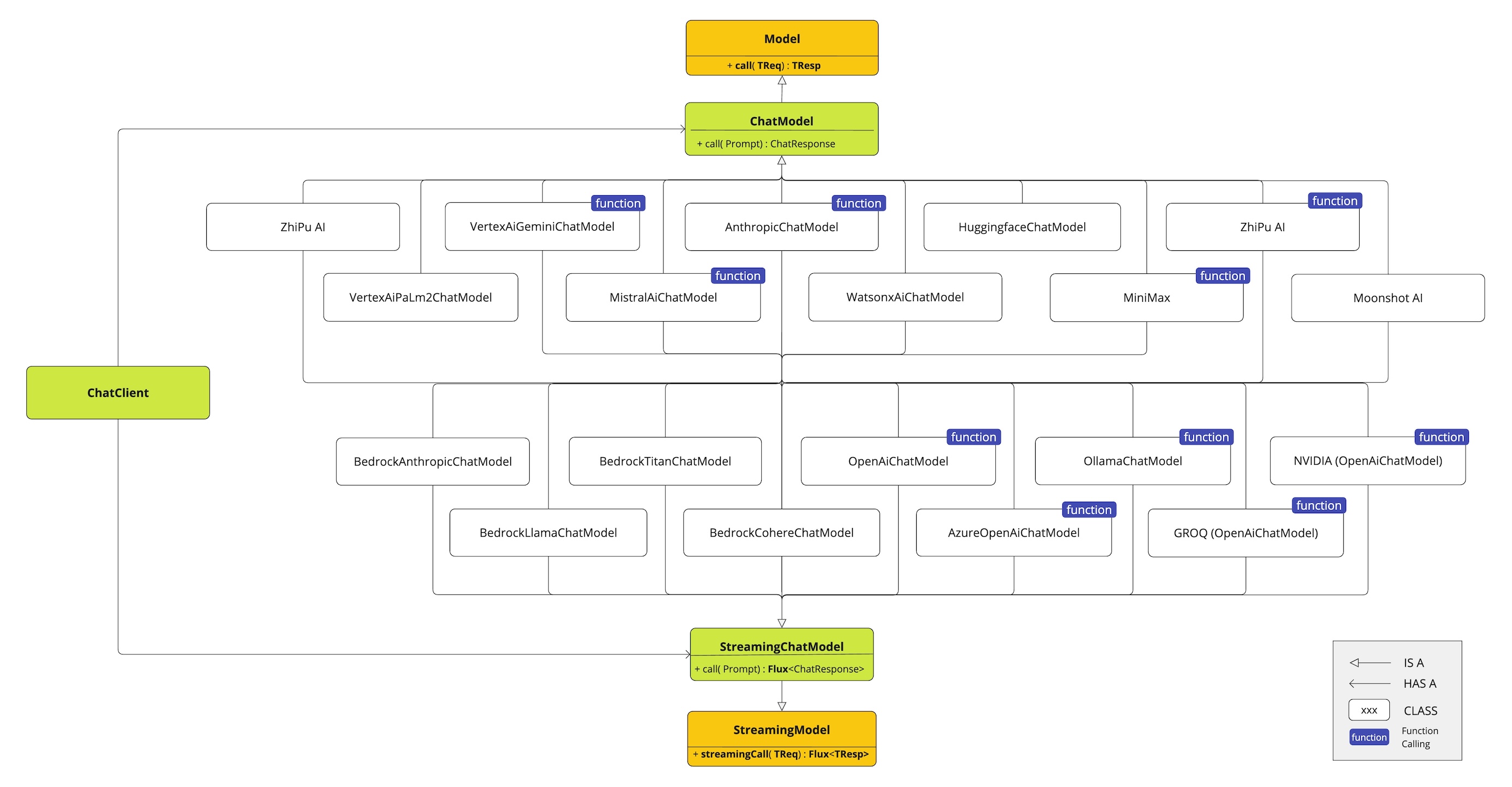
문서에서 ChatClient는 ChatClient.Builder로 생성하는 방식을 중심으로 설명한다. 이게 중요한 이유는 기본 설정을 중앙에서 잡기 좋기 때문이다.
예를 들어 다음과 같은 구성이 가능하다.
- 기본 시스템 프롬프트 지정
- 특정
ChatModel에 맞춘 클라이언트 분리 - 기본 advisor 설정
- 공통 옵션 주입
문서 예제 중에는 모델별 ChatClient를 각각 Bean으로 노출하는 패턴도 나온다. 이건 꽤 실용적이다.
예를 들어,
- OpenAI용
ChatClient - Anthropic용
ChatClient
를 각각 만들어 두면 서비스 계층에서 용도별로 나눠 쓸 수 있다. 공급자별 SDK를 직접 매번 만지는 것보다 훨씬 깔끔하다.
ChatClient는 멀티 모델 전략에도 잘 맞는다
문서에서 눈에 띄는 부분 중 하나는 mutate() 기반 파생 구성이다. 기본 API/모델 설정을 복제한 뒤, base URL이나 API key, 모델 옵션만 바꿔 다른 클라이언트를 만들 수 있다.
이건 실무에서 꽤 유용하다.
- 같은 코드 구조로 여러 공급자를 비교할 때
- 요약용/분석용 모델을 분리할 때
- 비용과 품질 기준으로 라우팅할 때
즉 Spring AI는 “모델 하나에 하드코딩된 앱”보다, 멀티 모델 구성을 스프링스럽게 정리하는 길을 열어 둔다.
동기 호출과 스트리밍을 함께 생각해야 한다
문서에서도 ChatClient는 동기와 스트리밍 프로그래밍 모델을 모두 지원한다고 설명한다. 이 차이는 UI와 사용자 경험에서 매우 크다.
동기 호출이 좋은 경우
- 관리자용 내부 도구
- 배치 처리
- 결과를 한 번에 내려줘도 되는 API
- 분류, 요약, 추출 같은 백엔드 작업
스트리밍이 좋은 경우
- 채팅 UI
- 긴 답변이 필요한 사용자 경험
- 응답이 늦으면 체감 품질이 떨어지는 서비스
처음엔 동기 호출부터 붙이고, 사용자 대면 화면이 생기면 스트리밍으로 넘어가는 편이 현실적이다.
ChatClient 하나만 안다고 끝나지 않는 이유
중요한 건 ChatClient가 출발점이지 종착점은 아니라는 점이다. 실제 앱은 금방 다음 질문으로 넘어간다.
- 대화 기록은 어디에 둘까?
- 검색 결과는 언제 프롬프트에 넣을까?
- 모델이 도구를 호출하게 만들까?
- 공통 전처리/후처리를 어디에 붙일까?
이때 이어지는 것이 Advisors, Chat Memory, Tool Calling, RAG다. 그래서 ChatClient를 이해할 때는 단독 클래스보다 확장의 허브로 보는 편이 맞다.
실무에서 추천하는 첫 번째 구조
처음 Spring AI를 붙이는 프로젝트라면 이런 식의 단계가 무난하다.
1단계
ChatClient.Builder주입- 가장 단순한
prompt().user(...).call().content()성공
2단계
- 시스템 프롬프트 분리
- 공통 설정을 Builder에 모으기
- 에러 처리와 로깅 추가
3단계
- advisor 붙이기
- 메모리 또는 RAG 연결
- 필요 시 tool calling 추가
이 흐름의 장점은, 처음부터 구조를 과하게 복잡하게 만들지 않으면서도 이후 확장 포인트를 남겨 둔다는 점이다.
한 문장으로 정리하면
ChatClient는 Spring AI에서 가장 먼저 배워야 하는 API이자, 이후 Tools·RAG·Advisors로 확장되는 중심 지점이다.
즉 이 클래스를 잘 이해하면 “Spring AI로 모델 한 번 호출하는 법”만 배우는 게 아니라,
- 프롬프트를 어떻게 구조화할지
- 공통 설정을 어디에 둘지
- 멀티 모델 구성을 어떻게 가져갈지
- 나중에 어떤 확장을 붙일지
까지 자연스럽게 이어진다.
마무리
Spring AI를 시작할 때 ChatClient부터 보는 건 우연이 아니다. 여기서 Spring AI의 기본 문법과 사고방식이 거의 다 드러난다.
- 프롬프트는 메시지 조립이다.
- 호출은 fluent API로 구성된다.
- Builder는 공통 구성을 모으는 자리다.
- ChatClient는 이후 RAG와 Tools, Advisors로 이어지는 출발점이다.
다음 글에서는 ChatClient만으로는 해결되지 않는 문제, 즉 최신 문서와 외부 지식을 어떻게 모델 응답 안으로 끌어오는가를 다루는 RAG 이야기를 이어가 보겠다.