Spring AI 시작하기: BOM, 저장소, 의존성에서 막히지 않는 법
title: "Spring AI 시작하기: BOM, 저장소, 의존성에서 막히지 않는 법" slug: "spring-ai-2-getting-started" status: "draft" series: "Spring AI 2.0 읽는 순서" order: 2 description: "Spring AI 프로젝트를 시작할 때 꼭 알아야 하는 Spring Boot 버전, Maven Central, snapshot 저장소, spring-ai-bom, 기능별 의존성 선택 기준을 정리한 글." tags: ["Spring AI", "Spring Boot", "Maven", "Gradle", "Java"] source_docs:
- "downloads/spring-ai-reference-2.0-ko/getting-started.html"
- "downloads/spring-ai-reference-2.0-ko/upgrade-notes.html"
Spring AI를 처음 붙일 때 가장 흔한 실패는 코드보다 설정에서 나온다.
- 어떤 Spring Boot 버전을 써야 하는가
- Maven Central만으로 되는가
- snapshot 저장소는 언제 필요한가
- 의존성 버전은 직접 맞춰야 하는가
- Chat, Embeddings, Vector Store 중 무엇을 먼저 넣어야 하는가
문서 자체는 이 정보를 잘 담고 있지만, 처음 읽는 사람에게는 조금 흩어져 보일 수 있다. 그래서 이 글에서는 실제로 프로젝트를 시작할 때 필요한 최소한의 판단 기준만 먼저 정리해 보겠다.
가장 먼저: 지원 버전부터 맞춘다
Spring AI 2.0 기준으로 문서에서 먼저 확인해야 하는 건 Spring Boot 호환 범위다.
현재 기준 핵심 포인트는 다음과 같다.
- Spring Boot 3.4.x / 3.5.x 지원
- 정식 릴리스는 보통 Maven Central만으로 충분
- milestone이나 snapshot을 쓰는 경우에만 추가 저장소 설정 필요
이 순서를 지키면 시작부터 불필요하게 복잡해지지 않는다.
개인적으로는 특별한 이유가 없다면 초반에는 무조건 이렇게 권한다.
- Spring Boot 안정 버전 사용
- Spring AI 정식 릴리스 사용
- Maven Central만 사용
spring-ai-bom으로 버전 정렬
처음부터 snapshot을 잡는 건 기능이 꼭 필요할 때만 해도 늦지 않다.
Spring Initializr로 시작해도 되나
된다. 오히려 가장 빠른 출발점이다.
start.spring.io에서 프로젝트를 만들 때 AI Model, Vector Store 관련 의존성을 함께 고를 수 있기 때문에, “빈 Spring Boot 프로젝트에서 하나씩 추가”하는 것보다 실수가 적다.
다만 Initializr로 생성했다고 끝은 아니다. 결국 프로젝트가 커지면 다음을 직접 이해해야 한다.
- 어떤 모델 공급자 스타터를 넣었는지
- 임베딩이 필요한지
- 벡터 스토어를 쓸지
- 추후 RAG나 Tool Calling으로 확장할지
즉 Initializr는 출발을 쉽게 해 주지만, 의존성 구조를 이해하는 일까지 대신해 주지는 않는다.
저장소 설정: 정식 릴리스면 단순하게 간다
Spring AI 문서에서 꽤 실용적인 포인트가 하나 있다. 정식 버전은 보통 Maven Central만 보면 된다.
이 말은 중요하다. 많은 개발자가 Spring 계열 프로젝트를 시작할 때 습관적으로 milestone, snapshot 저장소를 미리 다 넣어 두는데, 실제로는 그럴 필요가 없는 경우가 많다.
정식 릴리스
정식 릴리스를 쓴다면 보통 다음 정도면 충분하다.
- Maven: central 사용
- Gradle:
mavenCentral()사용
즉 처음엔 저장소보다 의존성 선택과 버전 정렬에 집중하는 편이 낫다.
snapshot / milestone이 필요한 경우
반대로 다음 상황이면 추가 저장소 설정이 필요할 수 있다.
- 최신 개발 버전 기능을 당장 써야 함
- 문서에서 소개된 기능이 아직 정식 버전에 안 들어옴
- 특정 버그 수정이 snapshot에만 반영됨
이 경우에는 Spring snapshot 혹은 milestone 저장소를 추가한다.
하지만 이 선택에는 대가가 있다.
- 팀 빌드 재현성이 떨어질 수 있음
- 사내 미러와 충돌할 수 있음
- 배포 파이프라인이 더 보수적으로 바뀔 수 있음
즉 “문서에 있으니 최신 snapshot부터 쓰자”보다, 정식 버전으로 가능한 선까지 먼저 가는 것이 대체로 낫다.
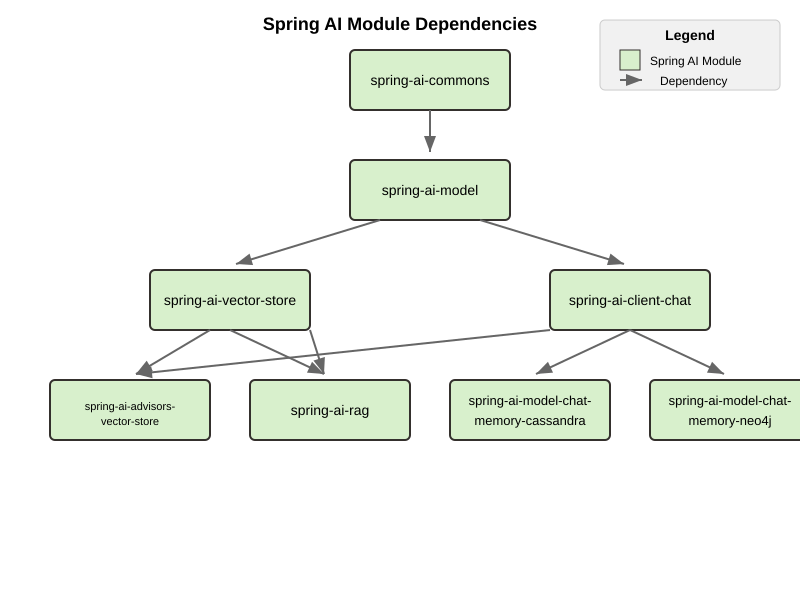
BOM을 쓰는 이유: 버전 정렬을 사람 손에서 빼기 위해서
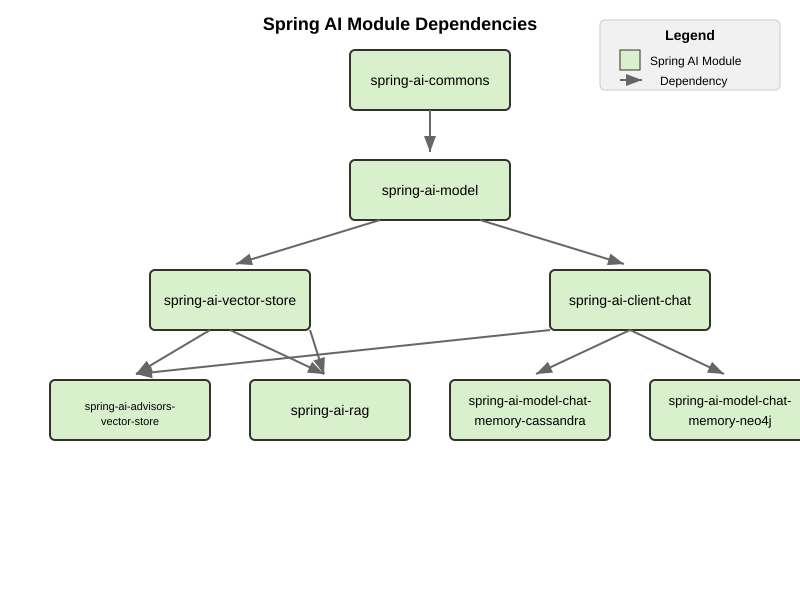
Spring AI를 붙일 때 가장 권장할 만한 습관은 spring-ai-bom을 쓰는 것이다.
BOM(Bill of Materials)은 관련 모듈의 권장 버전을 한 곳에서 맞춰 준다. 이게 왜 중요하냐면 Spring AI는 보통 단일 의존성 하나로 끝나지 않기 때문이다.
예를 들어 프로젝트가 커지면 이런 조합이 생긴다.
- Chat 모델 스타터
- Embeddings 스타터
- Vector Store 모듈
- Advisors 관련 모듈
- 경우에 따라 MCP, Evaluation, Observability 연동
이걸 전부 수동 버전으로 적기 시작하면, 어느 순간 버전 조합이 꼬이기 쉽다. BOM은 이 문제를 줄여 준다.
쉽게 말해 BOM은 “모듈 조합을 쓸 수는 있지만, 적어도 버전 정렬은 프레임워크가 추천하는 조합으로 가자”는 장치다.
처음 프로젝트에서 무엇을 넣어야 하나
처음부터 모든 기능을 넣는 건 좋지 않다. 목적별로 나누는 편이 낫다.
1) 가장 단순한 채팅/요약/분류 앱
이 경우엔 보통 다음만 있으면 된다.
- Spring Boot 기본 웹/앱 의존성
- 사용하는 모델 공급자의 chat 관련 의존성
ChatClient를 쓸 수 있는 기본 Spring AI 의존성
즉 “질문을 보내고 답을 받는” 앱은 생각보다 얇게 시작할 수 있다.
2) 문서 검색형 앱, 사내 지식 챗봇
여기서부터는 채팅만으로 부족하다.
추가로 보게 되는 것이 보통 다음이다.
- Embeddings
- Vector Store
- RAG 관련 모듈
- 문서 적재를 위한 ETL 파이프라인 고려
초기 단계에서는 여기까지가 가장 흔한 확장 경로다.
3) 외부 시스템과 상호작용하는 에이전트성 앱
예를 들어 일정 생성, 데이터 조회, 내부 API 호출, 워크플로우 트리거 같은 걸 붙이고 싶다면 다음을 보게 된다.
- Tool Calling
- Advisors
- 경우에 따라 MCP
이 시점부터는 “모델 호출”보다 권한 경계와 도메인 로직 설계가 더 중요해진다.
팀 환경에서 자주 놓치는 부분
문서에도 나오는 내용인데, 실제 팀 환경에서는 Maven mirror 설정이 종종 발목을 잡는다.
특히 사내 저장소를 mirrorOf="*"처럼 강하게 걸어 둔 경우,
Spring snapshot 저장소 접근이 막히는 문제가 생길 수 있다.
이 문제는 정식 릴리스를 쓴다면 아예 피해 갈 수 있다. 그래서 다시 말하지만, 특별한 이유가 없다면 정식 버전 + Maven Central 조합이 가장 스트레스가 적다.
현실적인 시작 템플릿
개인적으로 Spring AI를 처음 붙이는 프로젝트라면 이런 식으로 생각하는 게 좋다.
단계 1. 제일 먼저 성공해야 할 것
- 애플리케이션이 뜬다.
- 모델 한 번 호출이 된다.
ChatClient로 응답을 받는다.
단계 2. 그다음 붙일 것
- 시스템 프롬프트 분리
- 구성 속성 정리
- 에러 처리/타임아웃/로깅
단계 3. 필요가 생기면 확장할 것
- RAG
- Tool Calling
- Advisors
- MCP
- Observability / Evaluation
중요한 건, 처음부터 모든 개념을 한 번에 넣지 않는 것이다. Spring AI는 범위가 넓어서 욕심내면 오히려 구조가 흐려진다.
요약하면 이렇게 시작하면 된다
Spring AI를 처음 붙일 때 가장 무난한 경로는 아래다.
- Spring Boot 3.4.x 또는 3.5.x 사용
- 정식 릴리스 사용
- Maven Central만 사용
spring-ai-bom으로 버전 관리- 첫 번째 목표는
ChatClient한 번 성공시키기 - RAG, Tools, MCP는 두 번째 단계부터 붙이기
이 경로의 장점은 단순하다. 설정 문제로 시간을 덜 쓰고, 더 빨리 첫 작동 버전을 만들 수 있다.
마무리
Spring AI 입문에서 진짜 중요한 건 “모든 기능을 아는 것”이 아니라, 어떤 순서로 붙이면 덜 망하는지 아는 것이다.
그 순서는 대체로 이렇다.
- 버전 맞추기
- 저장소 단순화하기
- BOM 쓰기
- 첫 번째 ChatClient 호출 성공시키기
- 그다음에 RAG나 Tools로 확장하기
다음 글에서는 바로 그 첫 실전 API인 ChatClient를 중심으로, Spring AI 코드가 어떤 느낌으로 작성되는지 정리해 보겠다.