Observability, Evaluation, Upgrade Notes를 같이 봐야 하는 이유
title: "Observability, Evaluation, Upgrade Notes를 같이 봐야 하는 이유" slug: "spring-ai-2-observability-evaluation-upgrade" status: "draft" series: "Spring AI 2.0 읽는 순서" order: 9 description: "Spring AI 2.0의 Observability, LLM-as-a-Judge, Evaluation Testing, Upgrade Notes를 함께 묶어 운영 단계에서 꼭 봐야 할 포인트를 정리한 글." tags: ["Spring AI", "Observability", "Evaluation", "Testing", "Upgrade"] source_docs:
- "downloads/spring-ai-reference-2.0-ko/observability/index.html"
- "downloads/spring-ai-reference-2.0-ko/guides/llm-as-judge.html"
- "downloads/spring-ai-reference-2.0-ko/api/testing.html"
- "downloads/spring-ai-reference-2.0-ko/upgrade-notes.html"
- "downloads/spring-ai-reference-2.0-ko/api/effective-agents.html"
Spring AI를 처음 붙일 때는 대개 여기까지 생각이 닿지 않는다.
- 일단 호출이 되면 되고
- RAG가 붙으면 좋고
- Tool Calling이 돌아가면 꽤 멋져 보인다
하지만 운영 단계에 들어가면 질문이 완전히 달라진다.
- 왜 이번 응답은 이렇게 나왔는가
- 어느 단계에서 지연이 커졌는가
- 검색 품질이 지난주보다 왜 떨어졌는가
- 프롬프트 변경이 실제로 개선이었는가
- 버전 업그레이드가 어디를 깨뜨릴 수 있는가
이 지점에서 같이 봐야 하는 문서가 바로 Observability, Evaluation, Upgrade Notes다.
개인적으로는 이 셋을 따로 보는 것보다, 운영 가능한 AI 애플리케이션을 만들기 위한 한 묶음으로 보는 편이 훨씬 실용적이라고 생각한다.
Observability가 먼저 필요한 이유
LLM 앱은 내부 동작이 쉽게 블랙박스가 된다. 모델 응답만 보고 있으면 어디서 문제가 생겼는지 알기 어렵다.
Spring AI의 관찰 가능성 문서는 이 문제를 꽤 넓게 다룬다.
- Chat Client 메트릭
- Chat Model 메트릭
- Tool Calling 데이터
- EmbeddingModel 메트릭
- Vector Store 메트릭
- prompt / completion 관련 데이터
이게 중요한 이유는, 문제 지점을 계층별로 나눠 볼 수 있게 해 주기 때문이다.
예를 들면 이런 구분이 가능해진다.
- 모델 호출 자체가 느린가
- Tool Calling 단계가 병목인가
- 임베딩 생성이 느린가
- Vector Store 검색이 느린가
- 토큰 사용량이 갑자기 늘었는가
즉 Observability는 보기 좋은 대시보드가 아니라, 품질 문제를 분해하는 지도다.
Tool Calling과 Vector Store 메트릭을 같이 봐야 한다
문서에서 도구 호출과 벡터 스토어가 관찰 대상에 들어가는 점이 특히 좋다. 실제 AI 앱은 모델 한 번만 호출하고 끝나지 않기 때문이다.
예를 들어 응답이 느릴 때, 원인은 여러 군데일 수 있다.
- 모델 응답 지연
- 도구 호출 지연
- 벡터 검색 지연
- 재귀 Advisor로 인한 추가 호출
관찰 가능성이 없으면 사용자는 그냥 “AI가 느리다”라고 느끼지만, 개발자는 원인을 구분하기 어렵다. Spring AI는 적어도 이 구분의 틀을 제공한다.
평가(Evaluation)를 별도로 운영해야 하는 이유
관찰 가능성이 “무슨 일이 일어났는가”를 보여 준다면, 평가는 “그 결과가 좋은가”를 따로 묻는다. 이 둘은 겹치지 않는다.
응답 시간이 빨라도 품질이 나쁠 수 있고, 로그가 잘 남아도 답변이 부정확할 수 있다.
llm-as-judge.html과 testing.html을 같이 읽으면 이 차이가 분명해진다.
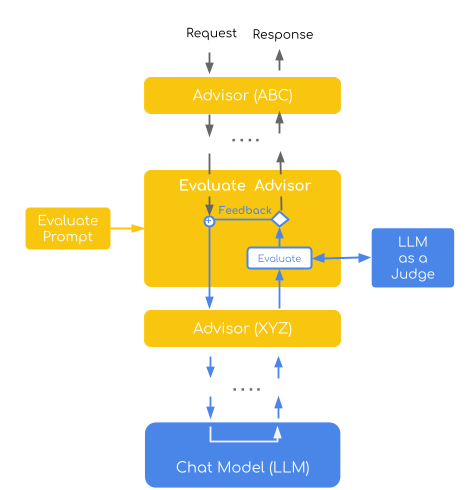
LLM-as-a-Judge
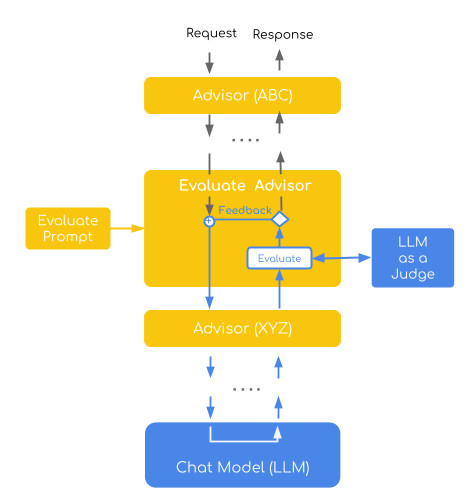
모델 응답을 또 다른 평가 기준으로 점검하는 방식이다.
문서에서는 SelfRefineEvaluationAdvisor 같은 패턴을 다루는데, 이건 단순 체크리스트를 넘어서 응답 품질을 다시 평가하고 보정 흐름에 연결할 수 있게 한다.
Evaluation Testing
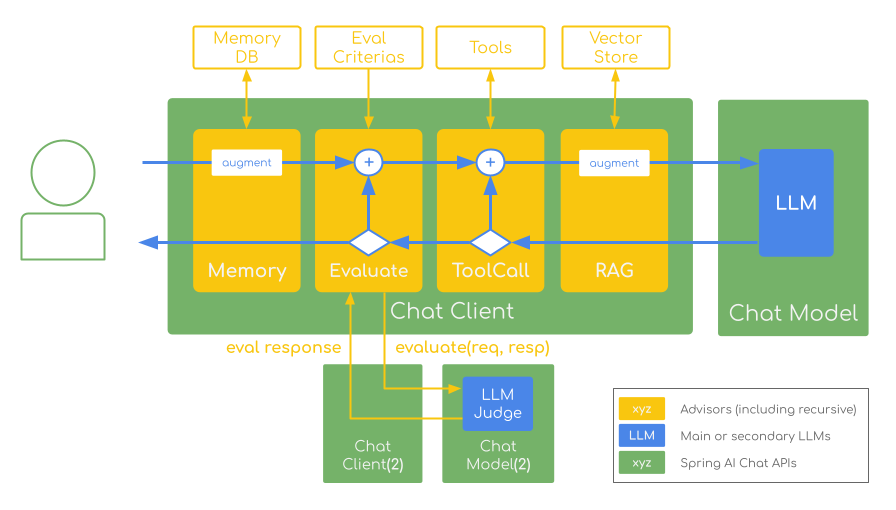
RelevancyEvaluator, FactCheckingEvaluator 같은 개념은 통합 테스트나 회귀 테스트에 특히 유용하다.
즉 프롬프트나 검색 전략을 바꾼 뒤에도,
- 관련성은 유지되는지
- 사실성은 악화되지 않았는지
- 특정 시나리오에서 품질이 무너졌는지
를 비교 가능한 형태로 볼 수 있다.
평가를 안 붙이면 생기는 문제
많은 팀이 프롬프트를 바꾸고 나서 “이번이 더 나아 보인다”는 감각으로만 판단한다. 하지만 LLM 앱은 입력이 다양해서 직감만으로는 품질 변화를 놓치기 쉽다.
예를 들어 이런 일이 생긴다.
- 응답이 더 친절해졌지만 근거성이 떨어짐
- 검색 문맥이 늘어났지만 정답률은 오히려 하락함
- 모델 변경 뒤 비용은 줄었지만 fact checking이 악화됨
그래서 관찰 가능성과 별도로 평가 데이터셋과 기준을 운영해야 한다.
Upgrade Notes를 꼭 같이 읽어야 하는 이유

Spring AI 2.0은 빠르게 변해 온 프로젝트라, 업그레이드 노트가 실무에서 꽤 중요하다. 특히 아래 같은 내용이 그냥 넘어가기 쉬운데 실제로는 크다.
- artifact ID 변경
- package / module 변경
- MCP Java SDK 업그레이드
- auto-configuration 동작 변화
- deprecated API와 breaking changes
- snapshot / milestone 저장소 관련 주의점
즉 버전 업은 dependency 숫자만 바꾸는 일이 아니다. 모델 연동, ToolCallback API, 자동 설정, 스타터 구성까지 함께 흔들릴 수 있다.
개인적으로는 업그레이드 노트를 릴리스 직전에만 보는 습관이 별로 좋지 않다고 본다. 오히려 설계 초반부터 “이 영역은 앞으로도 자주 변할 수 있다”는 감각을 주기 때문이다.
운영 단계에서 추천하는 최소 습관
Spring AI를 프로젝트에 붙였다면, 적어도 아래 정도는 초반부터 가져가는 편이 좋다.
1) 기본 메트릭을 켠다
- 모델 호출 시간
- 토큰 사용량
- 도구 호출 횟수와 지연
- 벡터 검색 지연
2) 대표 시나리오 평가셋을 만든다
- FAQ 몇 개
- 문서 검색 질문 몇 개
- 사실 검증이 중요한 질문 몇 개
크지 않아도 된다. 중요한 건 반복 비교가 가능해야 한다는 점이다.
3) 프롬프트/RAG 변경 전후를 기록한다
“왜 좋아졌는지”보다 “무엇을 바꿨고 무엇이 달라졌는지”를 남겨야 회귀를 잡을 수 있다.
4) 업그레이드 전에 노트를 먼저 읽는다
특히 milestone / snapshot 또는 MCP 관련 변경이 있으면 더 그렇다.
Effective Agents 문서와 연결되는 지점
effective-agents.html을 같이 보면, 왜 평가와 관찰 가능성이 에이전트형 시스템에서 더 중요해지는지도 이해된다.
체인, 라우팅, 오케스트레이터-워커, 평가자-최적화자 패턴처럼 단계가 많아질수록,
- 어디서 비용이 늘었는지
- 어느 단계가 실패했는지
- 어떤 패턴이 실제로 품질을 개선했는지
를 보지 못하면 구조만 복잡해지고 이득은 불분명해진다.
즉 에이전트성 패턴은 화려한 흐름보다, 측정과 평가가 붙을 때만 운영 가능한 구조가 된다.
한 문장으로 정리하면
Observability는 “무슨 일이 일어났는가”를 보여 주고, Evaluation은 “그 결과가 좋은가”를 검증하며, Upgrade Notes는 “내가 무엇을 깨뜨릴 수 있는가”를 미리 알려 준다.
이 셋을 같이 봐야 Spring AI 애플리케이션이 실험을 넘어 운영 단계로 간다.
마무리
Spring AI 2.0 문서를 읽다 보면 ChatClient, RAG, Tools, MCP 같은 주제가 먼저 눈에 들어온다. 그건 당연하다. 눈에 잘 보이는 기능이기 때문이다.
하지만 실제 운영에서 오래 남는 것은 보통 다른 질문들이다.
- 왜 이 응답이 나왔는가
- 좋아졌다는 근거가 있는가
- 업그레이드하면 무엇이 바뀌는가
그래서 시리즈의 마지막은 기능 소개보다 이 운영 축으로 닫는 편이 더 맞다고 느꼈다. Spring AI를 계속 쓸 생각이라면, 결국 여기까지 와야 한다.