RAG를 Spring AI에서 구현하면 뭐가 쉬워지나
LLM 앱이 데모를 벗어나 실무로 들어가는 순간 가장 빨리 부딪히는 문제가 있다.
“모델이 우리 문서를 모른다.”
조금 더 정확히 말하면 문제는 세 가지다.
- 긴 문서를 한 번에 다 넣기 어렵다.
- 최신 정보를 기본 모델이 알지 못한다.
- 사실 정확도가 필요한 질문에서 환각이 치명적일 수 있다.
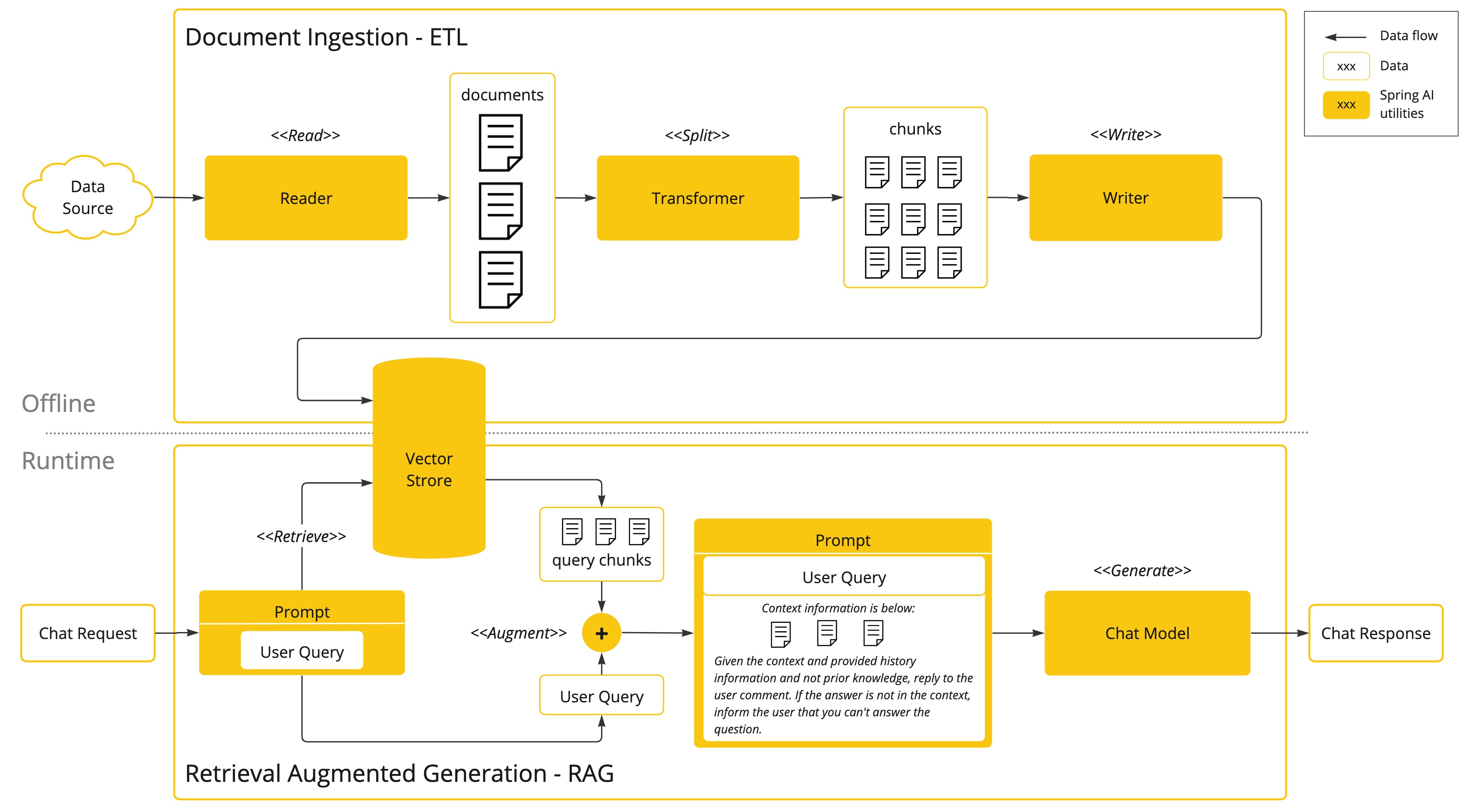
Spring AI 문서도 RAG(Retrieval Augmented Generation)를 바로 이 한계를 다루는 기술로 설명한다. 그리고 흥미로운 점은, Spring AI가 RAG를 단순한 패턴 소개 수준이 아니라 Advisor API와 Vector Store 추상화를 통해 꽤 구조적으로 연결해 둔다는 점이다.
RAG를 너무 거창하게 생각할 필요는 없다
RAG를 처음 접하면 시스템이 복잡해 보이지만, 핵심 아이디어는 생각보다 단순하다.
- 사용자의 질문과 관련 있는 문서를 먼저 찾는다.
- 그 문서 조각을 프롬프트 문맥에 붙인다.
- 모델은 그 문맥을 바탕으로 답한다.
즉 “모델이 원래 알고 있는 것에만 기대지 말고, 지금 필요한 자료를 검색해서 같이 읽힌다”가 RAG의 핵심이다.
그래서 RAG는 특히 이런 상황에 잘 맞는다.
- 사내 문서 검색
- 고객지원 지식베이스
- 정책/약관 질의응답
- 제품 문서 기반 어시스턴트
- 최신 내부 데이터 기반 응답
Spring AI에서 RAG가 쉬워지는 지점
Spring AI 문서의 장점은 RAG를 “직접 다 짜야 하는 구조”로만 설명하지 않는다는 데 있다. 바로 사용할 수 있는 흐름으로 Advisor 기반 접근을 제시한다.
대표적으로 문서에 나오는 것이 QuestionAnswerAdvisor다.
예제 흐름은 대략 이렇다.
1ChatResponse response = ChatClient.builder(chatModel)2 .build().prompt()3 .advisors(QuestionAnswerAdvisor.builder(vectorStore).build())4 .user(userText)5 .call()6 .chatResponse();7이 코드가 보여 주는 포인트는 명확하다.
ChatClient는 여전히 호출의 중심이다.- RAG는 별도 거대한 엔진보다
advisor로 붙는다. - 핵심 준비물은
VectorStore다.
즉 Spring AI는 RAG를 “모델 호출 바깥의 완전히 별도 세계”로 만들지 않고, 기존 채팅 호출 파이프라인에 삽입되는 단계로 다룬다.
Vector Store는 왜 필요한가
RAG에서 가장 핵심적인 저장소는 일반 DB가 아니라 VectorStore다.
이유는 문서를 키워드만으로 찾는 게 아니라, 질문과 의미적으로 가까운 문서 조각을 찾아야 하기 때문이다. 이를 위해 문서와 질문을 임베딩으로 바꾸고, 그 벡터 사이의 유사도를 비교한다.
Spring AI는 다양한 벡터 스토어를 지원하지만, 중요한 건 개별 제품 이름보다 공통 역할을 이해하는 것이다.
Vector Store는 대체로 이런 일을 한다.
- 문서 청크와 메타데이터 저장
- 임베딩 벡터 저장
- 유사도 검색 수행
- 필터 조건 적용
즉 RAG의 “검색층”을 담당한다.
실제로는 문서 적재가 절반이다

RAG를 처음 붙이는 팀이 자주 놓치는 건, 검색보다 적재가 더 어렵다는 사실이다. 모델이 잘 답하려면 문서를 그냥 통째로 넣는 게 아니라, 적절한 단위로 잘라서 정제하고 메타데이터를 붙여 저장해야 한다.
그래서 Spring AI 문서에서 ETL Pipeline과 Vector Databases 페이지가 RAG와 나란히 읽혀야 한다.
여기서 봐야 하는 질문은 이런 것들이다.
- 어떤 문서를 넣을 것인가
- 얼마나 작은 청크로 나눌 것인가
- 어떤 메타데이터를 붙일 것인가
- 언제 재색인할 것인가
- 필터링은 어떤 기준으로 할 것인가
즉 RAG 품질은 모델보다 문서 준비와 검색 설계에서 크게 갈린다.
필터링이 중요한 이유
Spring AI 문서 예제에서 실무적으로 유용한 부분 하나는 SearchRequest와 필터 표현식이다. 단순히 “가까운 문서 몇 개”만 찾는 게 아니라, 검색 대상을 제한할 수 있다.
예를 들어 이런 상황이 있다.
- 제품 문서와 운영 문서를 분리하고 싶다.
- 특정 카테고리 문서만 검색하고 싶다.
- 권한에 따라 검색 범위를 다르게 하고 싶다.
- 최신 버전 문서만 우선 보고 싶다.
문서 예제처럼 advisor 생성 시 기본 검색 조건을 둘 수도 있고, 요청 시점에 필터를 주입할 수도 있다. 이건 운영 단계에서 꽤 중요하다. RAG는 검색 범위가 넓을수록 항상 좋은 게 아니기 때문이다.
프롬프트 템플릿도 품질에 큰 영향을 준다
문서에는 PromptTemplate을 커스터마이즈하는 예제도 나온다. 이 부분이 중요한 이유는, RAG가 단순히 문서를 붙인다고 끝나지 않기 때문이다.
모델에 어떤 태도로 답하게 할 것인지도 같이 설계해야 한다.
예를 들면 이런 규칙들이다.
- 문맥에 없으면 모른다고 말하라.
- “제공된 정보에 따르면” 같은 군더더기를 줄여라.
- 문맥에 있는 정보만 근거로 답하라.
- 필요한 경우 인용 방식이나 형식을 강제하라.
이런 규칙이 없으면 검색은 잘되어도 답변 품질이 불안정해질 수 있다.
RAG가 모든 문제를 해결하진 않는다
RAG를 붙였다고 해서 자동으로 정확도가 보장되지는 않는다. 오히려 아래 같은 문제가 새로 생긴다.
- 엉뚱한 청크가 검색된다.
- 문맥이 너무 길어져 핵심이 묻힌다.
- 권한 없는 문서가 섞일 수 있다.
- 중복 문서 때문에 답변이 흐려진다.
그래서 RAG는 “검색을 붙였다”보다, 검색 품질을 운영한다는 감각이 더 중요하다.
Spring AI가 좋은 점은 이 흐름을 Advisor, VectorStore, ETL, Prompt 조합으로 나눠 생각할 수 있게 해 준다는 것이다.
처음 구현할 때 추천하는 경로
Spring AI로 RAG를 처음 붙인다면, 개인적으로는 아래 순서를 추천한다.
1단계: 아주 작은 문서셋으로 시작
- 내부 문서 몇 개만 넣는다.
- 청크 크기를 단순하게 잡는다.
QuestionAnswerAdvisor로 가장 기본 흐름을 붙인다.
2단계: 메타데이터와 필터 추가
- 문서 유형
- 버전
- 권한 범위
- 서비스 영역
이 정도 메타데이터만 있어도 검색 품질이 많이 달라진다.
3단계: 프롬프트와 평가 다듬기
- 문맥 없는 답변 금지
- 출처 표기 방식 정리
- 검색 실패 시 fallback 정책 정리
처음부터 대규모 문서셋과 복잡한 파이프라인으로 가면, 어디서 품질이 깨지는지 추적하기 어려워진다.
한 문장으로 정리하면
Spring AI에서 RAG가 쉬워지는 이유는, 검색 기반 문맥 주입을 ChatClient 바깥의 별도 해킹이 아니라 Advisor와 Vector Store를 통한 정식 애플리케이션 흐름으로 다룰 수 있기 때문이다.
그래서 개발자는 다음을 분리해서 생각할 수 있다.
- 모델 호출
- 문서 적재
- 유사도 검색
- 필터링
- 프롬프트 규칙
이 분리는 유지보수와 운영에서 큰 차이를 만든다.
마무리
RAG는 LLM의 부족한 최신성, 긴 문서 처리 한계, 정확도 문제를 보완하는 가장 현실적인 방법 중 하나다. 그리고 Spring AI는 이걸 단순 개념이 아니라 실제 코드 구조로 연결해 둔다.
핵심만 다시 정리하면 이렇다.
ChatClient가 호출의 중심이다.QuestionAnswerAdvisor가 RAG 진입점을 단순하게 만든다.VectorStore는 검색층이다.- ETL과 청킹, 메타데이터 설계가 품질을 좌우한다.
- 프롬프트 규칙까지 함께 설계해야 실무에서 버틴다.
다음 단계로 넘어가면 자연스럽게 Tool Calling과 Advisors를 더 깊게 보게 된다. 그 지점부터는 “검색하는 앱”을 넘어, “외부 시스템과 상호작용하는 AI 애플리케이션” 설계가 시작된다.