Dynamic Tool Discovery — 도구가 많아질수록 왜 오히려 성능이 나빠질까
Dynamic Tool Discovery — 도구가 많아질수록 왜 오히려 성능이 나빠질까
툴 호출 기반 에이전트를 만들다 보면 처음에는 단순하다.
- 날씨 조회 도구 하나
- 일정 조회 도구 하나
- 검색 도구 하나
이 정도면 모델에게 모든 툴 정의를 매번 보여 줘도 큰 부담이 없다. 하지만 실제 시스템은 금방 커진다. Slack, GitHub, Jira, 내부 API, MCP 서버까지 붙기 시작하면 도구 수가 수십 개, 많게는 수백 개가 된다.
이 시점부터는 이상한 일이 생긴다.
도구가 많아질수록 에이전트가 더 똑똑해지는 게 아니라, 오히려 둔해질 수 있다.
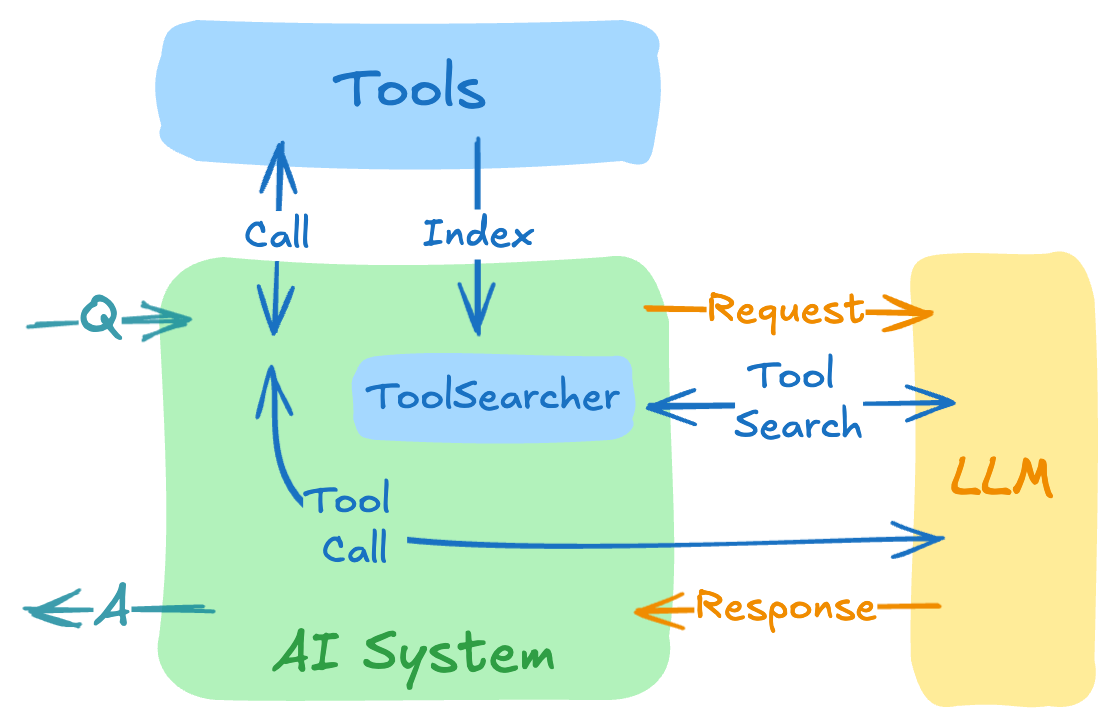
Spring AI의 Dynamic Tool Discovery 글은 바로 이 문제를 다룬다. 핵심은 “처음부터 모든 도구를 다 보여 주지 말고, 검색 도구 하나만 먼저 주고 필요할 때 찾아오게 하자”는 것이다.
문제는 토큰만이 아니다
원문은 큰 도구 집합을 한 번에 모델에게 주는 방식의 문제를 세 가지로 정리한다.
- 컨텍스트 비대화
- 도구 선택 혼선
- 비용 증가
이 중 많은 사람이 비용 문제만 떠올리지만, 사실 더 무서운 건 도구 선택 정확도 저하다. 비슷한 이름의 도구가 많아질수록 모델은 헷갈리기 쉽다. 30개 이상의 툴이 한꺼번에 붙으면, 단순히 프롬프트가 길어지는 걸 넘어 선택 문제 자체가 어려워진다.
즉 Dynamic Tool Discovery는 최적화 트릭이 아니라, 대규모 툴 환경에서의 정확도 유지 전략이기도 하다.
기본 아이디어는 정말 단순하다
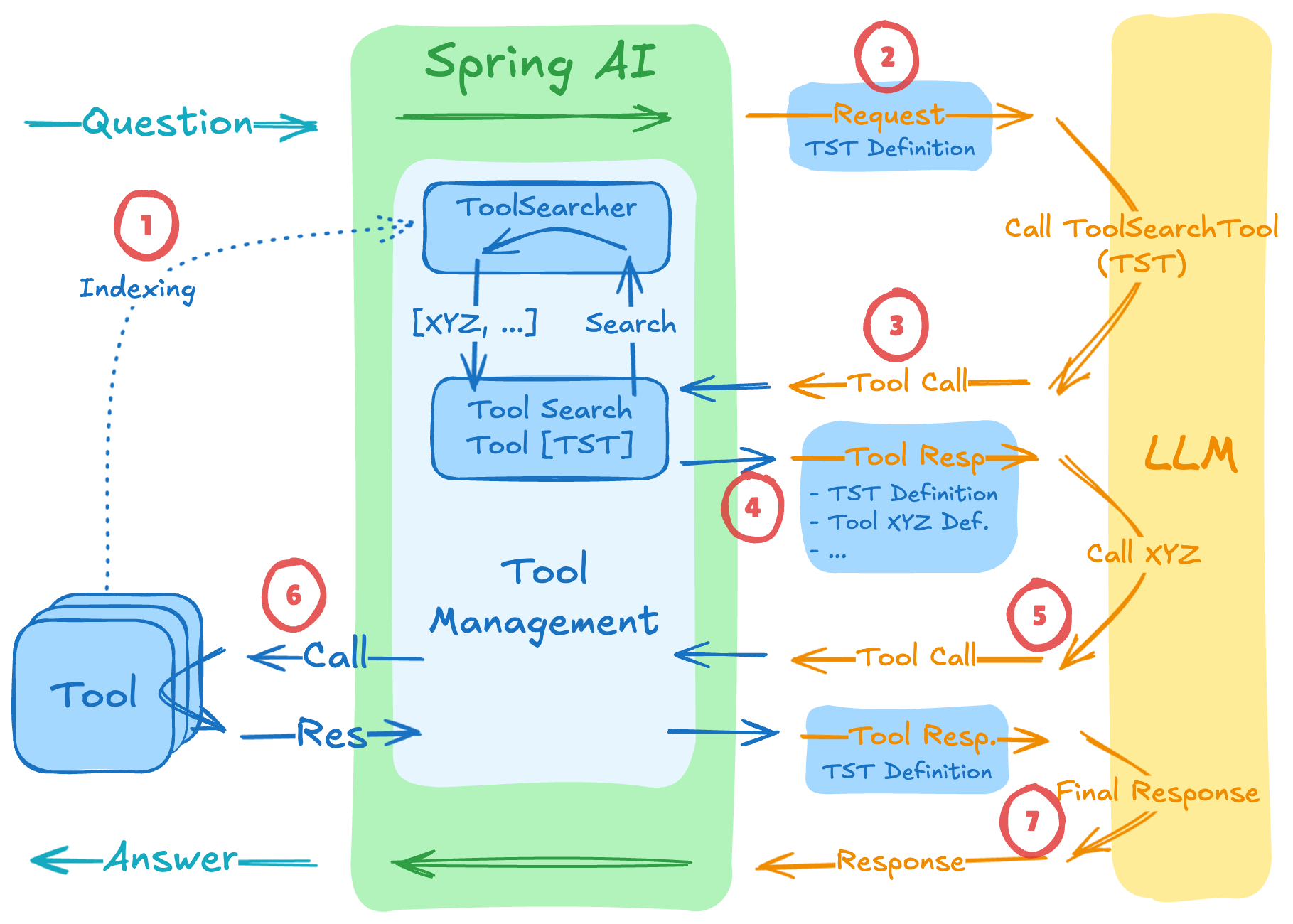
Anthropic이 제안한 Tool Search Tool 패턴의 요지는 아래와 같다.
- 처음에는 모든 도구 정의를 주지 않는다.
- 검색용 도구 하나만 준다.
- 모델이 필요할 때 “어떤 도구가 필요한지” 검색한다.
- 검색 결과로 나온 관련 도구 정의만 다음 요청에 넣어 준다.
- 그제서야 실제 도구 호출을 수행한다.
즉 전체 도구 목록을 upfront로 다 밀어 넣는 게 아니라, 필요할 때 필요한 도구만 문맥에 확장하는 방식이다.
Spring AI가 이걸 portable하게 만든다
원문에서 중요한 포인트는 이 패턴이 Anthropic에만 묶인 게 아니라는 점이다. Spring AI는 Recursive Advisors를 활용해 이 방식을 다양한 모델 공급자에서 구현할 수 있게 한다.
즉 OpenAI, Anthropic, Gemini, Ollama 같은 여러 모델에서도 같은 패턴을 적용할 수 있다.
이건 꽤 중요하다. 왜냐하면 툴 검색 패턴은 특정 모델의 “비밀 능력”이 아니라, 애플리케이션 레벨에서 설계 가능한 라우팅 전략이라는 뜻이기 때문이다.
ToolCallAdvisor와의 차이
기본 Tool Calling 흐름에서는 보통 ToolCallAdvisor가 모든 등록 도구의 정의를 모델에게 함께 보낸다. 작은 앱에서는 이게 간단하고 좋다.
하지만 도구 수가 커지면 이 방식의 약점이 드러난다.
Dynamic Tool Discovery는 여기서 한 단계 더 들어간다. ToolSearchToolCallAdvisor가 중간에 끼어들어,
- 처음에는 검색 도구만 노출하고
- 검색 결과에 맞는 실제 도구 정의만 점진적으로 추가한다
즉 재귀적 툴 호출 루프를 그대로 활용하되, 도구 주입 정책만 더 똑똑하게 바꾼 것에 가깝다.
검색 전략을 바꿀 수 있다는 점도 실용적이다
원문은 ToolSearcher 인터페이스를 통해 여러 검색 전략을 소개한다.
- Semantic / Vector 기반 검색
- Lucene 같은 키워드 검색
- Regex 기반 패턴 검색
이 설계가 좋은 이유는 도구 발견 문제를 “모델이 알아서 다 해주겠지”로 두지 않고, 검색 인프라 문제로 분리하기 때문이다.
예를 들어,
- 자연어 질의가 많으면 벡터 검색
- 도구 이름 규칙이 명확하면 키워드/정규식 검색
- 둘을 섞는 하이브리드 방식도 가능
즉 Dynamic Tool Discovery는 단순한 프롬프트 트릭이 아니라, 꽤 구조적인 시스템 설계다.
성능 수치가 말해 주는 것
원문은 OpenAI, Anthropic, Gemini에서 34~64% 수준의 토큰 절감 예시를 보여 준다. 물론 예비 측정이고 절대 수치로 받아들일 필요는 없지만, 방향성은 충분히 설득력 있다.
특히 눈여겨볼 점은 이 패턴이 요청 횟수는 늘릴 수 있어도, 전체 토큰 사용량은 크게 줄일 수 있다는 것이다.
즉 trade-off는 이렇다.
- 요청 수는 조금 늘 수 있다
- 하지만 각 요청은 훨씬 가벼워진다
- 그리고 모델은 덜 헷갈린다
대규모 툴 환경에서는 이 교환이 꽤 괜찮다.
언제 특히 유용한가
1) MCP 서버를 여러 개 붙이는 환경
툴 수가 폭발하기 쉬운 대표적인 경우다.
2) 기업 내부 API가 많은 환경
도구 종류는 많은데, 한 요청에서 실제 필요한 건 극히 일부인 경우.
3) 멀티도메인 에이전트
예: 일정/문서/이슈/커뮤니케이션/검색이 모두 섞인 에이전트.
4) 비용보다 정확도가 더 중요한 환경
도구 선택 혼선을 줄이는 것 자체가 큰 가치가 있다.
한계도 분명하다
물론 모든 프로젝트가 이 패턴을 당장 도입할 필요는 없다.
- 도구가 5개 이하라면 오히려 과할 수 있다.
- 검색 품질이 낮으면 필요한 도구를 못 찾을 수 있다.
- 한 번에 다 주는 단순 흐름보다 디버깅 지점이 늘어난다.
즉 작은 프로젝트에는 기본 ToolCallAdvisor가 더 낫고, 툴 수가 커질수록 Dynamic Tool Discovery의 가치가 커진다고 보는 편이 맞다.
이 글에서 가져가야 할 핵심
Dynamic Tool Discovery의 핵심은 단순하다.
도구 수가 많아질수록, 전부 보여 주는 전략은 점점 나빠진다.
그래서 필요한 건 모든 툴을 upfront로 주입하는 방식이 아니라, 검색을 거쳐 필요한 것만 점진적으로 여는 방식이다.
이건 토큰 최적화이기도 하지만, 더 근본적으로는 대규모 툴 환경에서의 에이전트 정보 아키텍처에 가깝다.
마무리
Spring AI의 Dynamic Tool Discovery는 “도구를 덜 보내서 싸진다” 수준의 이야기가 아니다. 더 본질적으로는,
- 툴 집합이 커질 때
- 모델이 덜 헷갈리게 하고
- 필요한 능력만 제때 드러내는
구조를 제공한다.
에이전트가 점점 더 많은 시스템과 연결될수록, 이런 구조는 선택이 아니라 필수가 될 가능성이 크다.
Series Links
- Spring AI Agentic Patterns (Part 1): Agent Skills 한국어 정리
- AskUserQuestionTool 한국어 정리
- TodoWriteTool 한국어 정리
- Subagent Orchestration 한국어 정리
- A2A Integration 한국어 정리
- Dynamic Tool Discovery (원문)
- Tool Argument Augmentation 한국어 정리